











 Share on media
Share on media

Understand the basics of Web Scraping, from sending HTTP requests to storing and exporting data.
Web Scraping is an automated technique that is used to extract large amounts of unstructured publicly available data and convert it into a more structured format. The web scraping tools offer their benefits over various key industries, like market research and lead generation. With the web scraping tools, businesses can gather contact information, along with collecting competitive pricing and lead generation.
What is Web Scraping?
Web Scraping is an automated technique that is used to extract large amounts of unstructured data from websites. The tools transform the unstructured data into a structured format, like spreadsheets or databases. It uses various automated software, often called “bots” or “crawlers“, to load a webpage, parse HTML codes, and gather specific information, like images, prices, or texts.
Web scrapers offer significant benefits in automatic data collection and offer high-quality and structured data from across the web. The tool help businesses with various key aspects, like competitive intelligence, price monitoring, lead generation, or finding email addresses from any website.
Benefits of Web Scraper
Key benefits of Web Scraper are as follows
- Accuracy & Reduced Human Error: The tool automates the data extraction process, ensuring consistency and reliability. It also helps in eliminating the various human errors in manual copying, like typos and missed data points.
- Automation and Time Saving: The tool collects vast amounts of data automatically in minutes, which would generally take weeks to perform manually.
- Competitive Monitoring: With the help of the tool, businesses can also track the competitive prices, product launches, and promotional strategies in real-time.
- Lead Generation and Sales: The tools can easily gather contact information, social media profiles, and company details to create a targeted marketing list.
- Market Analysis and Trends: The tool can also extract consumer sentiment, reviews, and market data to analyze and identify emerging trends.
Limitations of Web Scraping
The primary limitation of web scraping tools includes the following:
- Ethical and Legal Constraints: The main limitations of web scraping are the legal constraints. Scraping personal data can violate various data privacy laws like GDPR and CCPA. Using scraped data for commercial applications can also lead to copyright issues.
- Data Quality: The scraper tools can collect various noisy, irrelevant, or malfunctioning data, which requires time-consuming data cleaning.
- Technical Challenges: A web scraper may trigger a ban mainly because of the high volume of traffic from a single IP address. Automated systems can also be easily stopped by CAPTCHA.
- File Type Limitation: Most web scrapers have the capabilities to scrape HTML but struggle to extract data from documents like PDFs.
How Web Scraping Works?
The data scraping process of the tool is automated, which extracts a large amount of data from websites and converts unstructured data into a structured format. The web scraping process includes the following steps:
- Step 1: The scraping tool sends an HTTP GET request to the server of the targeted website, which mimics a standard web browser.
- Step 2: The server responds by sending back the raw HTML code of the targeted page.
- Step 3 (Optional): For a dynamic website, which loads content using JavaScript, the scraper uses headless browsers to fully render the page before extraction.
- Step 4: The tool parses the HTML into a navigational structure and uses selectors to pinpoint and pull specific data points, like product name and prices.
- Step 5: The extracted data is cleaned and saved into usable formats, like CSV and Excel, for integration into databases or APIs.
Various other tools, like the Google Maps Scraping and Email Scraping, also follow the same fundamental process of Web Scraping to perform specialized tasks. Google Maps Scraping and Email Scraping tools can also be considered as the specialized sub-type of Web Scraping tools, which is focused on a specific data field or platforms, like collecting data from Google Maps or gathering email addresses from websites.
Key Components of Web Scraping
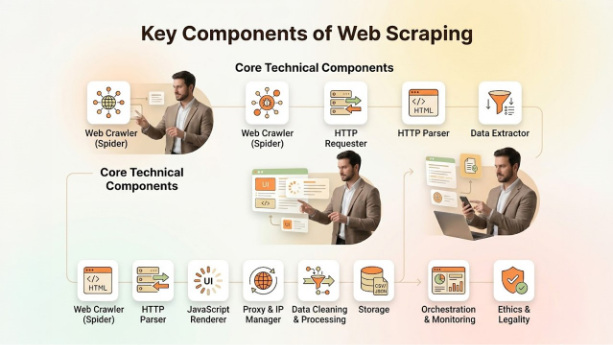
The components of web scraping can be categorized into three major sections, which include core technical components, operational & scaling components, and compliance & management.
The components of web scraping include:
- Core Technical Components
- Web Crawler (Spider): An automated script that explores the internet by following links to discover and index specific URLs.
- HTTP Requester: The HTTP Requester is responsible for sending requests to web servers.
- HTTP Parser: The module breaks down raw HTML into a more searchable “tree” structure. It allows specific elements to be located.
- Data Extractor: The logic, which uses CSS selectors, to pinpoint and pull specific data points, like price, name, and contact info.
- Operational & Scaling Components
- JavaScript Renderer: An essential component for modern websites, as it executes scripts to load dynamic content, which cannot be done using a basic HTML fetcher.
- Proxy & IP Manager: The module rotates IP addresses to prevent blacklisting. It also helps in bypassing rate limits and geoblocking.
- Data Cleaning & Processing: It is a pipeline that is used to remove noise, normalize formats, and validate data queries before storage.
- Storage: It is the destination for structured data that can be exported in various formats, like CSV and JSON.
- Compliance & Management
- Orchestration & Monitoring: The tool schedules scraping tasks, manages retries, and tracks success rate and error rates.
- Ethics & Legality: The module adheres to the site’s “robots.txt” file and is critical to avoid legal action or server overload.
Real-World Use Cases of Web Scraping
The web scraper tools offer various applications across multiple industries. The tool enables efficient data collection for key applications like market research, price monitoring, and AI model training. A web scraper can also be used to track product availability, monitor consumer sentiment, and aggregate real estate listings. Some key real-world applications of web scraping include:
- Market Research & Analysis: The tool helps in collecting a large volume of data on trends, consumer feedback, and product reviews, which can be used to understand market demand and sentiments.
- Lead Generation and Sales: The scrapers help in collecting public contact details, which are available on the company’s website or directories, to build a list of qualified prospects. The web scraper tools also help in collecting structured data for lead generation, which is like email scraping services, but with enhanced capabilities.
- Machine Learning Training: Large-scale scraping tools gather texts, images, and data required to train and validate AI models, like Large Language Models.
- Price Monitoring & Intelligence: Companies usually scrape the websites of competitors to monitor prices, along with tracking discounts and adjusting their own pricing strategies.
Key Considerations for Web Scraping
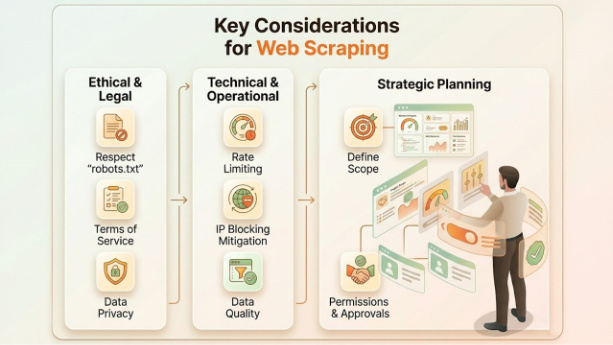
The main consideration for web scraping includes respecting the “robots.txt” file and the Terms and Services. It is also essential to avoid overloading the server with high-frequency requests and to protect user privacy by not collecting personal data.
Ethical & Legal Considerations
- Respect “robots.txt”: It is essential to check for the “robots.txt” in the root directory to check the disallowed path on the website.
- Terms of Service: It is important to review the policy of the website to ensure that scraping is allowed and that it does not breach any agreements.
- Data Privacy and Personal Data: Avoiding the scraping of personal, sensitive, and confidential information is important to avoid legal violations.
Technical & Operational Best Practices
- Rate Limiting: It is important to avoid overwhelming the servers by spacing out requests. It also prevents service disruptions and detection.
- IP Blocking Mitigation: The tool utilizes IP rotation techniques to circumvent aggressive rate limits.
- Maintaining Data Quality: Ensure data accuracy and reliability by better structuring the scrape.
Strategic Planning
- Define Scope: Clearly define the primary and secondary use cases of the data, which ensures the collection of efficient and relevant data.
- Request Permission: Consider reaching out to the owner of the site for permission for large-scale or proprietary data.
Conclusion
Web scraping is a computer program that is used to collect or extract a large amount of data from multiple websites. The tool uses automated software for data scraping process, which is often referred to as the “bots” or “crawlers“, that loads the webpages, parses HTML codes, and gathers specific information. The web scraping tools help in collecting high-quality and structured data from across the web, and benefit the business with various key aspects, like competitive intelligence and price monitoring. The web scraping tool works by sending an HTTP GET request to the server. The tool also parses the HTML into navigational structures and extracts the data into a usable and clean format.
Frequently Asked Questions
Is web scraping legal?
Scraping publicly available data is generally legal but scraping personal or protected data is illegal.
What is the difference between web scraping and web crawling?
Web crawling is the automated tool which discovers and indexes web pages, while web scraping refers to the targeted extraction of specific data from websites.
What is HTML parsing?
HTML parsing is the process by which a web browser or computer program takes raw HTML code and converts it into a structured model, called the Document Object Model (DOM).
How do websites prevent scraping?
Websites prevent scraping by implementing various measures, like rate limiting, CAPTCHA, and bot detection services. Some websites also use advanced solutions like specialized bot management and TSL/SSL fingerprinting to protect data from web scraping tools.
Can we replace APIs with web scraping?
Yes, technically, one can replace APIs with web scraping, but it does not act as a like-for-like substitute. Web scraping generally acts as a fallback or a supplement to an official API.





